大数据提高

流式数据框架
流式处理平台使得应用程序能够对源源不断进入系统的数据进行分析和处理。现实生活中有许多借助于流式大数据来实现其系统目标的案例。例如,在医院系统中,我们可以通过检测病人的生理构造的变化情况,来预测是否应该为病人进行实时的生命体征状态监控。这些功能的实现都离不开数据框架的支持,下面将对流式数据中采用的主流框架进行分析,并在某些性能方面与应用于其他数据结构的框架进行对比。
Storm框架
Apache Storm是一款免费的开源分布式实时计算系统。Storm能够可靠的处理大量的流式数据。现在Storm所做的工作,好比就是Hadoop在批处理数据阶段所做的工作。Storm简单易用,可以兼容任何的编程语言。Storm是一个由一系列用户所编写的消息和应用程序代码所组成的平台。Storm中非常重要的一个概念就是“流”。所谓的“流”就是许许多多无界的数据的元组组成的序列。用户可以通过使用Storm提供的两个概念(spout、bolt),将一组已经存在的流(例如:日志消息)传递到新的流(例如:趋势信息)中去。spout和bolt都提供了接口,用户必须实现这些接口来完成自己的逻辑功能的实现。
Storm架构
在一个Storm集群中主要有两种类型的节点[8]。主节点和处理节点。
主节点运行一个称之为Nimbus的进程。其负责在集群中部署代码、分派任务、监视任务的进展情况以及回报崩溃的情况。它也同时运行一个UI进程。UI即用户界面,它提供了一个网站给用户以实时观测集群的状态以及管理拓扑和拓扑上的节点。在目前的Storm版本中,会有这样的情况出现:即当主节点崩溃后,处理节点仍然在工作,但是重新配置集群等操作在此期间就是无法进行了,除非我们去重启主节点。也许未来的Strom版本会对这一问题进行改进。
进程节点,运行一个称之为Supervisor的进程。这个Supervisor一直在监听者分派给这台机器的任务。它根据需求动态的开始和停止工作。这个需求是基于主节点分派给这台机器的任务。在一个进程节点中的若干个任务,都执行一系列的拓扑。例如一个或多个spout和bolt、metrics。鉴于此情况。一个拓扑topology很可能是分布在一个集群的若干个机器之间。进程节点同样也运行一个LogViewer进程,该进程可以用来查看网站上的浏览日志。
主节点与进程节点之间的协同工作是通过Zookeeper集群来完成的。在Zookeeper中可以存储和检索有关分配任务情况、进程处理健康状态以及集群的状态。
用户需要手动的将应用程序的代码打包成jar包,并且传递给主节点。将jar包分派给进程节点的工作进程是通过进程节点和主节点之间的直连网络来实现的。图11就展现了Storm架构的主要组成部分。Spark框架
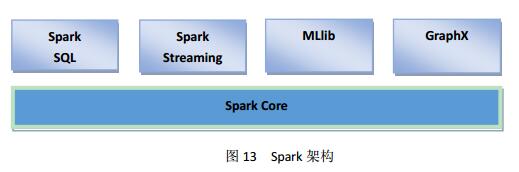
Spark是一个高速、通用的集群计算系统。它为Java、Scala、Python以及R语言都提供了应用程序接口。它也是最佳的支持通用执行图的引擎。不仅如此,Spark也提供了非常丰富的插件工具,其中包括为SQL设计的Spark SQL、结构化的数据处理工具、机器学习库MLlib、图像处理工具GraphX和Spark Streaming。
设计Sprak的目的就是为了解决许多Hadoop MapReduce处理框架所遗留下来的一些问题。Spark项目引进了一个新的概念:弹性分布式数据集(RDD)。该数据集使得数据在集群节点之间的存储和处理直接在内存中进行,从而极大的加快了效率。同时,也创建了一个有向无环图(DAG)实现其容错机制。当集群中的某一个节点崩溃后,可以转由另一个节点来接手处理原来节点所负责的事物。Spark最大的特点和优势就是减少了I/O读写所耗费的时间。在2014年sort benchmark上Spark刷新了记录。使用206个节点在23分钟之内成功排序了100TB的数据。而之前的记录则是由MapReduce保持的(使用210个节点在72分钟内排序同样数量的数据)。Spark兼容Hadoop的组件(如HDFS和Hive)并且可以使用YARN运行在Hadoop上。